Method
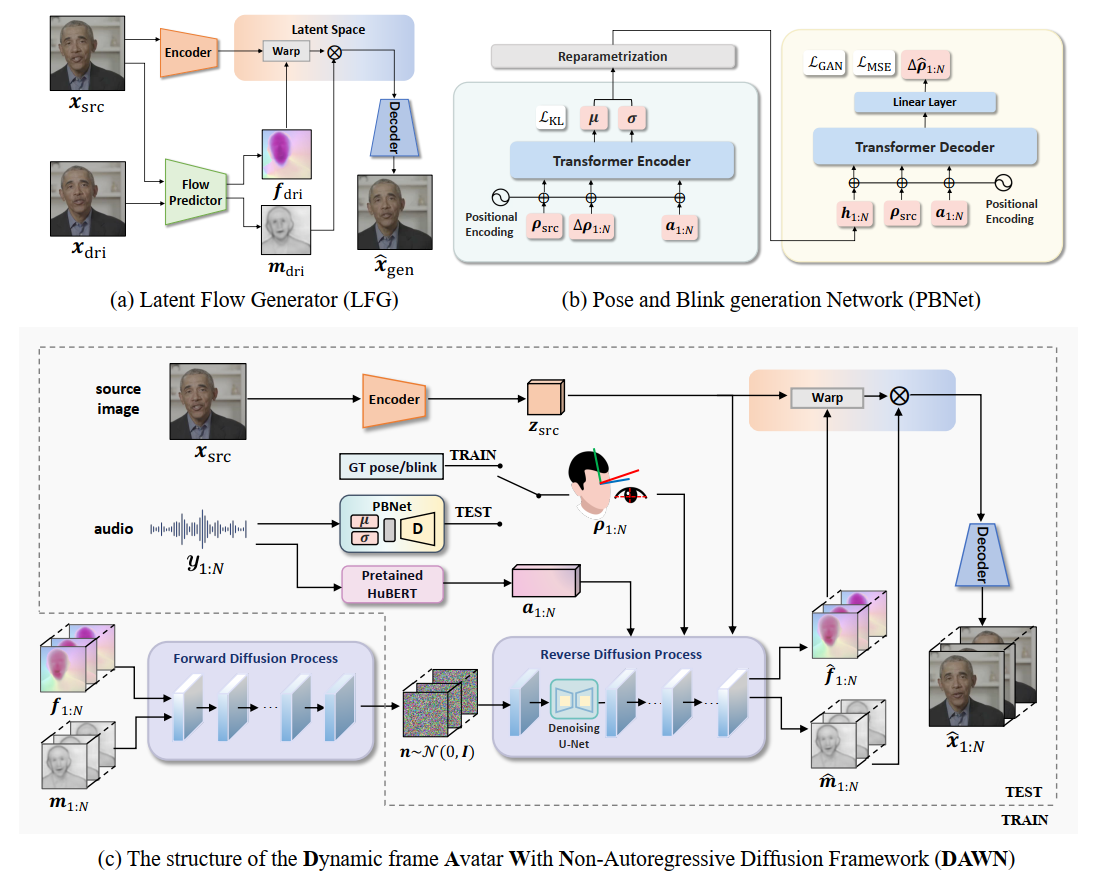
Overview of our proposed method. DAWN is divided into three main parts: (1) the Latent Flow Generator (LFG); (2) the conditional Audio-to-Video Flow Diffusion Model (A2V-FDM); and (3) the Pose and Blink generation Network (PBNet). First, we train the LFG to estimate the motion representation between different video frames in the latent space. Subsequently, the A2V-FDM is trained to generate temporally coherent motion representation from audio. Finally, PBNet is used to generate poses and blinks from audio to control the content in the A2V-FDM. To enhance the model's extrapolation ability while ensuring better convergence, we propose a novel Two-stage Curriculum Learning (TCL) training strategy.
Results
Overall Comparison
We compared the DAWN with several state-of-the-art methods, including Sadtalker, Audio2Head, Wav2Lip, Diffused Heads, . Our method evidently achieves the visual quality most similar to the ground truth, showcasing the most realistic and vivid visual effects. Compared to our method, SadTalker relies on the 3DMM prior, which limits its animation capability to the facial region only, resulting in significant artifacts when merging the face with the static torso below the neck. Additionally, SadTalker exhibits unnatural head pose movements and gaze direction, partially due to limited temporal modeling ability. Wav2Lip only drives the mouth region and cannot generate head poses or blinks. The Audio2Head fails to preserve the speaker's identity during generation. For the HDTF dataset, the Diffused Heads method collapsed due to the error accumulation.
Comparison with several state-of-the-art methods, both on CREMA and HDTF datasets (128*128).
Extrapolation validation
To evaluate the extrapolation capability of our method, we conducted experiments assessing the impact of inference length on model performance using the HDTF dataset. The inference length was varied from 40 to 600 frames in a single generation process. We produced videos of stable quality over varying inference lengths, which were significantly longer than the training video clips, indicating a strong extrapolation capability.
Extrapolation validation. The character and audio is selected from HDTF dataset (128*128).
Pose/blink Controllable Generation
Our method also enables the controllable generation of pose and blink actions. Users can either use pose and blink information generated by our PBNet or provide these sequences directly, such as by extracting them from a given video. Our method not only provides high-precision control over the pose/blink movements of the generated avatars, but also effectively transfers rich facial dynamics, including expressions, blinks, and lip motions.
Cross-identity reenactment, the character and audio is selected from HDTF dataset (128*128).
Ablation Study on the PBNet
We evaluate the effectiveness of the PBNet. The term "w/o PBNet" indicates that the PBNet module was removed from the architecture, requiring the A2V-FDM to simultaneously generate pose, blink, and lip motions from the audio by itself. It suggests that using the PBNet to generate the pose exclusively will provide the pose with more vividness and diversity. However, generating lip, head pose, and blink movement from audio simultaneously will cause a relatively static head pose, which severely impacts the vividness and naturalness.
The ablation study on the PBNet, the character and audio is selected from HDTF dataset (128*128).
Different Portrait Styles & Languages
For different styles: Our method is capable of generating avatars in multiple distinct styles. This is achieved by training exclusively on the HDTF (256*256) dataset.
Character: Generated by Stable Diffusion
Vocal Source: From HDTF dataset.
For different languages: It is worth noting that during the training, we used only English audio. This experiment aims to evaluate the generalization ability of our method. We tested the avatars with speech in Chinese, Japanese, Korean, French, and German. Additionally, we included two Chinese dialects: Hokkien and Cantonese.
Character: Generated by stable diffusion
Vocal Source: Chinese speech from Jun Lei , the founder of Xiaomi Technology.
Character: Generated by stable diffusion
Vocal Source: Japanese speech from Sakai Masato (堺 雅人), in the television series "Legal High"
Character: Generated by stable diffusion
Vocal Source: Korean speech, from
Character: Generated by stable diffusion
Vocal Source: German speech, from
Character: Generated by stable diffusion
Vocal Source: French speech, from
Website
Character: Generated by stable diffusion
Vocal Source: Speech in Cantonese, from Andy Liu in movie "Infernal Affairs". Cantonese also known as Yue Chinese (粤语), is one of the major Chinese dialect in the Guangdong province, Hong Kong, Macau.
Character: Generated by stable diffusion
Vocal Source: Speech in Hokkien by Xueling Sun, from Website. Hokkien, also known as Minnan (闽南语), is a Chinese dialect spoken in the southern part of Fujian province in China, as well as in Taiwan, Malaysia, Singapore.